Iterative Algorithms
Contents
Iterative Algorithms¶
The simplest types of algorithms have no iteration. They are just a set of instructions that happen in order. For example, image we are computing employee payroll. The instructions to determine the weekly wage would just be:
Get hours rate
Get number of hours worked
Multiply values together
There are no loops in this algorithm. We just complete the instructions from top to bottom. This is easy, but we cannot get very far without any iteration. The simplest iterative command is the while loop. The while loop says we need to do something repeatedly.
In our previous example for the Greatest Common Divisor algorithm, we needed to create multiple iterative loops. One of the loops happened when we needed to read in text from the user.
//Creates a buffer array
//Reads in characters until hitting newline or
//end of file
char* readFromStdin(){
//Create an array buffer
int bufferSize = 100;
char* buffer = malloc(sizeof(char)*bufferSize);
//Place characters into buffer starting at pos 0
int position = 0;
//Loop over characters
char temp;
temp = getchar();
while(temp != EOF && temp != '\n'){
buffer[position]=temp;
temp = getchar();
position++;
}
//Null Terminate the String
buffer[position]=0;
position++;
//Return the string we read in
return buffer;
}
When we write algorithms, there are a few questions we want to ask.
How much work does the algorithm do?
How much memory does the algorithm need?
Each of these main questions will have multiple parts in their answer. We will look at the readFromStdin function to see how to answer each of these questions. For now, we will do a few steps a little informally using rules of thumb. In a later section, we will lay out the formalities of this analysis.
The first question we want to look at is “how much work does the algorithm do?” To answer this we need a definition of what work is. It is hard for us to know exactly what the hardware of a computer will actually do. When we write c++ what does the processor do? We know it adds 1 to c but how? Does it do it in one hardware operation or does it need five? We don’t know.
Counting Operations¶
We will estimate the amount of work the code does by counting the operations done in the language we are writing our code in. We will look through the readFromStdin function and determine how many operations are needed to run it.
The first line of the function is int bufferSize = 100;. This line only does one thing. It sets the value of the variable named bufferSize to be equal to 100. We will say this line does 1 assignment operation. More specifically, we would say the = operation is executed 1 time.
The second line of code has more to take apart.
char* buffer = malloc(sizeof(char)*bufferSize);
The code executes from the inside out. That is the same way we should try to count the operations. The first thing on this line that needs to happen is the value of sizeof(char) needs to be computed. That is 1 execution of the sizeof operation. After that, we do a multiplication of that size with the value of bufferSize. This gets us one execution of the * operation. Once the multiplication is done, we get a call to malloc. There is 1 execution of the malloc operation. Lastly, we assign that result of malloc to the variable buffer. This is 1 assignment operations. The amount of work done by this line of code is shown in the table below.
Operation |
Time Executed |
|---|---|
|
1 |
|
1 |
|
1 |
|
1 |
That only accounts for the second line of the function. To get the total work done, we need to add the work done on the first line as well. That adds one more assignment operation.
Operation |
Time Executed |
|---|---|
|
1 |
|
1 |
|
1 |
|
2 |
The next line of the function is int position = 0;. This line adds one more assignment operator.
Operation |
Time Executed |
|---|---|
|
1 |
|
1 |
|
1 |
|
3 |
The next line does not add any operations. The command char temp; is telling the system memory is needed for the temp variable. This memory would be allocated as part of the function, so we don’t count it as an operation here. The following line is the operation, when this place in memory gets a value temp = getchar();. We update the counts for these additional operations.
Operation |
Time Executed |
|---|---|
|
1 |
|
1 |
|
1 |
|
4 |
|
1 |
Things get more complicated on the next line. We enter into a loop.
while(temp != EOF && temp != '\n'){
buffer[position]=temp;
temp = getchar();
position++;
}
With this block of code, we can no longer think one line at a time. The line temp = getchar() doesn’t just run once. It runs once for every iteration of the loop. Let’s start our analysis by picking a pretend input. Imagine the user has typed “Cat” followed by a newline. The following table shows how the code executes.
Execution Line |
Value |
Value |
Comments |
|---|---|---|---|
Before First |
|
|
Initialized already |
|
|
|
Condition is true |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Condition is true |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Condition is true |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Condition is false |
The word “Cat” had 3 letters in it. It was followed by a trailing newline. The while condition temp != EOF && temp != '\n' was tested 4 times. It was true three times and false once. The body of the loop executed fully 3 times. It executed every time the condition was true. It did not execute the time the condition was false. We can count the operations just for this loop on the input “Cat”. Note that temp != EOF is always true in this example, so temp != '\n' always runs. If the first part of an AND operation is true the second part does not need to be run.
Operation |
Time Executed |
|---|---|
|
8 |
|
4 |
|
4 |
|
3 |
|
6 |
|
3 |
|
3 |
Those are the totals, but only for the word “Cat”. We need to generalize this to make any overall conclusions. Instead, let’s say that the user typed an input with \(n\) characters not including the newline. We had \(n=3\) above. Then our table looks like the one below.
Operation |
Time Executed |
|---|---|
|
\(2(n+1)\) |
|
\(n+1\) |
|
\(n+1\) |
|
\(n\) |
|
\(2n\) |
|
\(n\) |
|
\(n\) |
In the case of the while condition temp != EOF && temp != '\n', it is not actually clear if the != will happen once or twice. It depends on if the last iteration stops on EOF or '\n'. When this happens we always assume the worst. If there are two options, we take the longer one. This gives us an upper estimate. We are not talking about the number of operations in term of a variable \(n\).
The total operations for all the lines of the file we have looked at so far are totalled below.
Operation |
Time Executed |
|---|---|
|
1 |
|
1 |
|
1 |
|
\(2n+4\) |
|
\(n+1\) |
|
\(2(n+1)\) |
|
\(n+1\) |
|
\(n+1\) |
|
\(n\) |
|
\(n\) |
There are still three lines left in the function. They are not in a loop. We just count them directly.
//Null Terminate the String
buffer[position]=0;
position++;
//Return the string we read in
return buffer;
We have 1 more assignment, increment, and bracket access. We also have one return statement. The total operations needed for this function are given in the table below.
Operation |
Time Executed |
|---|---|
|
1 |
|
1 |
|
1 |
|
\(2n+5\) |
|
\(n+1\) |
|
\(2(n+1)\) |
|
\(n+1\) |
|
\(n+1\) |
|
\(n+1\) |
|
\(n+1\) |
|
1 |
This table gives the full details of the function operation. We often want a summary of the function as a whole. To get this, we generalize to just operations. We total all the values in the table.
The total operations the function does is \(9n+16\) operations for an input with \(n\) characters. Traditionally, we call this function \(T(n)\). We would say readFromStdin has a runtime of \(T(n)=9n+16\) operations.
You will notice that although we call this runtime it is not actually a time! It is a estimation that predicts something about the time code will take to run. Every computer will run each operation in a different time. An Apple Computer with an M2 chip will compute a++ at a different speed then a Windows computer on an Intel processor. The number of operation is a more general estimation. The number of operations is defined by the code we wrote, not the hardware the code runs on. It still predicts something about the runtime.
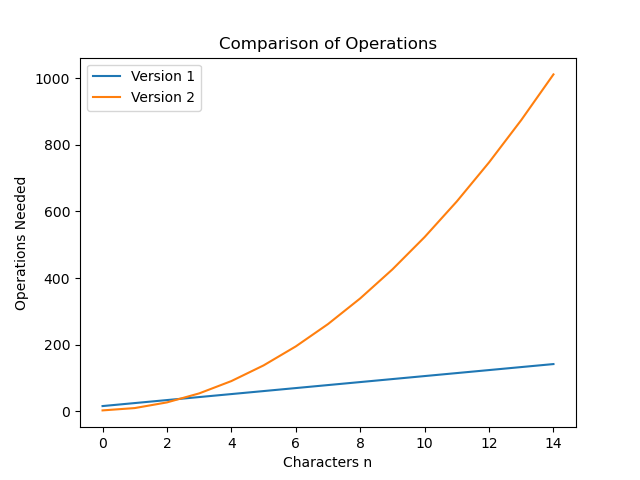
Imagine we had two versions of readFromStdin. We wanted to decide which to put into our program.
Option |
Runtime |
|---|---|
|
\(T_{1}(n)=9n+16\) |
|
\(T_{2}(n)=5n^2 + 2n + 3\) |
We may not know how many milliseconds an operation will take, but I can predict that Version 2 will be slower. It does more operations for most inputs, which implies it will take more time in practice. The following chart shows the number of operations on the y axis and the number of characters on the x axis. Notice how much faster \(T_{2}\) increases. This implies the real time to execute the code would at the same.
Counting Memory¶
We know how many operations the code will take. We also want to know how much memory it will use. We will copy the function definition but this time remove everything that is not related to memory.
char* readFromStdin(){
int bufferSize;
char* buffer = malloc(sizeof(char)*bufferSize);
int position;
char temp;
return buffer;
}
Only the lines shown above deal with memory allocation. There are two kinds of memory. The local memory used by the function itself and the heap memory. The local memory are variables that are created in the function and only live while the function is executing. The local variables are listed in the table below.
Variable Name |
Size (Bytes) |
|---|---|
|
4 |
|
8 |
|
4 |
|
1 |
We can find out how much memory a variable needs by called sizeof. The return value of sizeof is a unsigned long. When we print it, we use the code %lu.
int main(int argc, char** argv){
printf("int: %lu\n",sizeof(int));
printf("char: %lu\n",sizeof(char));
printf("char*: %lu\n",sizeof(char*));
return 0;
}
This function has no inputs, so we don’t have to worry about their memory usage. It does have a return value. The return type is char*. We already know that means it will need \(8\) bytes for that. When this function ends, it needs to return \(8\) bytes of data to the part of the program that called it.
The part of the memory usage we have not handled yet is malloc(sizeof(char)*bufferSize);. This creates memory on the heap. The heap is the area of the program where memory is dynamically allocated. This means we get memory when we ask for it and return that memory when we are done with it. The local memory was known to the compiler and it could set everything up at compile time. The program requests the memory on the heap as it executes and the Operating System assigned it as needed.
We know that bufferSize is hard-coded to be \(100\). We also know that a char requires 1 byte. The means we will be asking the Operating System for \(100\) bytes when this command is called.
A summary of our memory usage for the function is given below.
Inputs: 0 bytes
Returns: 8 bytes
Local Variables: 17 bytes
Heap Memory: 100 bytes
Notice that none of these are in terms of \(n\) the number of characters like the runtime was. This function always uses the same amount of memory regardless of the text the user types.
Function Overview¶
We have determined the the runtime of the readFromStdin() function is \(T_{1}(n)=9n+16\). We have also determined that the amount of memory needed during execution of the function \(117\) bytes total. When the function ends it will return \(8\) bytes.
We would call the runtime of this function linear. It is described by a linear function on the input size \(n\). A linear function describes a line. It has the format \(ax+b\) where \(a\) and \(b\) are both constants.
The memory usage of this function is constant. No matter what the function is called to do, it will always use the exact same amount of memory.
When working with pseudocode, we won’t be able to get answers as exact as these, but we can approximate them.